My Machine Learning-powered subject analyzer told me that you would open this post. Was it right?
The main challenge with building subject analyzers is to identify which features are relevant. Is it the subject’s length? A specific word? A combination of words?
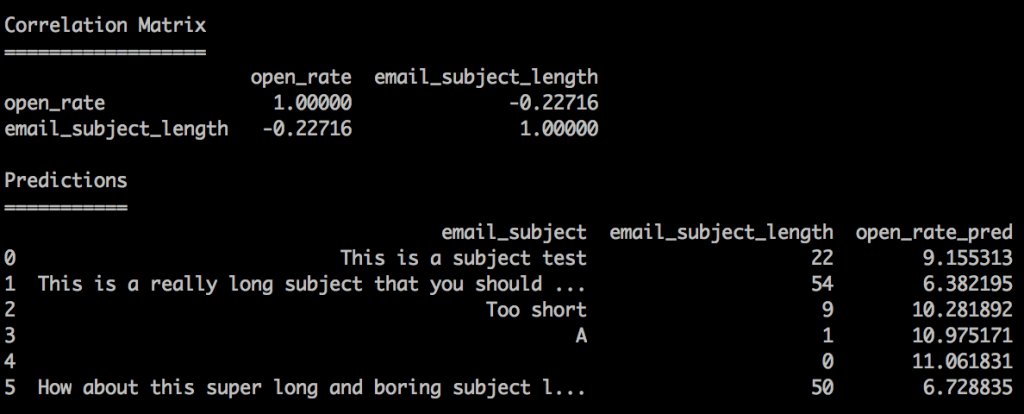
I took the easy route and used the subject’s length as a feature to predict open rates, using a Linear Regression model.
I’ve found a weak (but insightful) correlation between subject’s length and open rate: -0.22.
The longer the subject, the less likely it is that people will read it. Subjects like “Too short” has a predictive open rate of 10.28% over “This is a long subject that you should not read” with 6%.
How about the subject “A”? People will open an email with a click-bait type subject not because an ML algorithm said so, but because they are curious about it.
ML tools should evolve as we get more insights into our data. The more you know about your audience, what they like, when they act, the more effective ML tools you will build.
Click here to check out my simple subject analyzer’s code.

- Your Team Is Shipping Fast. That’s the Problem. - 02/21/26
- AI Moved the Bottleneck to Your Head - 02/19/26
- Stop Building AI Agents - 02/17/26